With the help of Semantic Web technologies, which ensure machine processability and interchangeability, we are able to apply semantic knowledge models and paths to organise and describe heterogeneous multimedia items and their context. Within this project, we developed integrated approach for ontology-based multimedia document management, which covers the process of automated modeling of semantic descriptions for multimedia objects and allows for the domain-specific customization of the used ontology. Furthermore, the proposed approach addresses the problems of data validation and consolidation to ensure semantic descriptions of proper quality. We demonstrate the practicability of our concept by a prototypical implementation of a service platform for personal information management applications.
The prevalent uncertainty and ambiguity of interpretation and interrelation of information sources and the various application scenarios led us to the concept of a stepwise information instantiation process. The subdivision of the knowledge modelling has several advantages over non-modular generation. As we cannot predict extent and quality of the available information about multimedia documents, direct inference from these sources would be quite mighty and monolithic. By dividing the generation process, we split the required rule base used for data transformation into more lightweight and manageable sets. Thus, separate rule sets can be configured and customised individually and independently, according to the application context, the input data, and the target schema.
Document modifying activities invoke the application of Update Rules to the knowledge model. In accordance to the instantiation process, the modeling of metadata about the activities themselves is also a configurable, rule-based transformation process to provide flexibility and allow for substitution of the used ontology model. To retrieve context information about a document’s usage, we integrated the generic context modeling component CroCo [Pietschmann et al., 2008], which gathers and models cross-application context data from available context providers (e.g., from desktop applications, like e-mail clients, authoring tools, etc.).
The semantic consolidation process considers data in the context of the whole knowledge base. In general, consolidation is necessary whenever the knowledge base has been changed or extended by any automated process. Depending on the actual application context, the set of rules for the detection of semantic conflicts and incompletion, as well as the metrics and threshold for duplication detection can easily be adjusted or replaced. If a decision for conflict or duplication resolving can be made automatically, the user does not need to intervene. If a clear decision cannot be assured, the user must be involved for case-related judging. To minimize additional effort whilst providing the user with a high degree of control, it is necessary to find a compromise between fully automatic, semi-automatic and manual solution of the data problems. Our approach provides a machine-readable as well as human-readable problem description of data problems, according to a purpose-made ontology, to allow for different solutions.
As a proof-of-concept and for evaluation of the developed approach a specifically designed architecture is used, which is prototypically implemented in Java according to the OSGi specification. The applied plug-in concept provides a high degree of extensibility and flexibility. There exist components for management and processing of the semantic data base and for import and analysis of media items. The diverse system components are implemented as OSGi Service Bundles, which makes it possible to install, register and start services at run-time and on demand. RDF and OWL processing and storage is based on the Jena Semantic Web Framework, including its inference support for the application of rules and reasoning services.
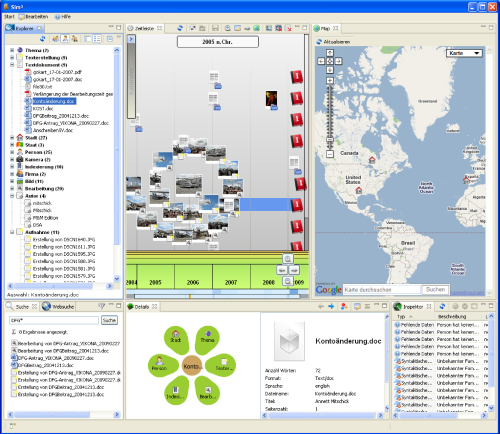
Based on the exemplary implementation of the K-IMM System, we set up a desktop application based on the Eclipse Rich Client Platform (RCP). The application allows for the unrestrained edition and creation of semantic descriptions, providing dynamically generated dialogs with appropriate data type verification. Resources which have relations to spatial or temporal information are visualized as pictograms in a geographical view (based on the Google Maps API) resp. a time-line view which can be zoomed smoothly for different levels of detail.