Vor dem Hintergrund der skizzierten Projektziele und Schwerpunkte und ausgehend von den Defiziten bestehender Ansätze bestand die Vision dieses Projektes in einem System, welches die Verwaltung multimedialer Dokumentensammlungen auf Basis semantischer Informationen ermöglicht und das Fundament für die Entwicklung innovativer Werkzeuge für das persönliche Informations- und Wissensmanagement (PIM) bildet. Auf Basis einer eingehenden Untersuchung des Standes der Technik und Forschung wurde ein Vorgehensmodell entwickelt, welches essentielle Mechanismen zur semantikbasierten Dokumentenverwaltung bietet. Die entwickelten Verfahren bilden die Grundlage für eine komponentenbasierte Architektur als technische Basis für die Entwicklung innovativer, semantikbasierter Anwendungen zur persönlichen Dokumentenverwaltung. Eine Reihe von Demonstratoren belegt den Mehrwert der erarbeiteten Konzepte und die Tauglichkeit der auf Basis der Architektur entwickelten Referenzimplementierung.
Zu den entwickelten Mechanismen für die semantikbasierte Dokumentenverwaltung zählen die semi-automatische Generierung semantischer Beschreibungen für persönliche, multimediale Dokumente, die Aktualisierung und Synchronisierung der semantischen Datenbasis in Bezug auf eine Dokumentensammlung und die systemgestützte Bereinigung und Konsolidierung der semantischen Datenbasis zur Sicherung der Datenqualität.
Der entwickelte Ansatz zur automatischen Generierung semantischer Beschreibungen für persönliche, multimediale Dokumente und deren Verwaltung beruht auf einem mehrstufigen, pipelinebasierten Modellierungsprozess als Abfolge verschiedener Datentransformationen
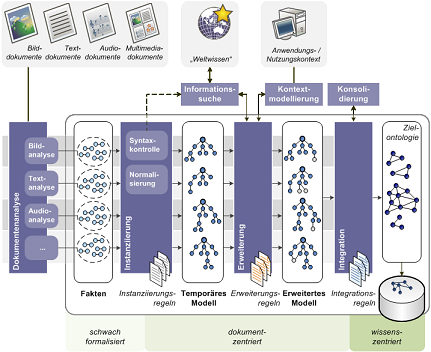
Ziel dieser Datentransformationen ist eine semantische Datenstruktur (Zielontologie), welche anwendungsspezifische Konzepte und Relationen zur Beschreibung und Kontextualisierung von Dokumenten enthält. In einem vorverarbeitenden Schritt, der Dokumentenanalyse, erfolgt für jedes einzelne der eingegebenen Dokumente die Identifikation des Medientyps und die entsprechende medientypspezifische Extraktion und Analyse relevanter Informationen. Die so gewonnenen Daten bilden die eigentlichen Eingabedaten für den folgenden Generierungsprozess. Dieser, auf dem "Pipe-and-Filter"-Architekturstil basierende Prozess, beinhaltet (1.) das Erstellen einer semantischen Basisbeschreibung aus ausgewählten Merkmalen und Informationen eingegebener Dokumente (Instanziierung), (2.) das Einbeziehen von verfügbarem Kontext- und "Weltwissen" (Erweiterung), und (3.) das Einbinden der temporären Modelle in die zentrale Datenbasis (Integration). Jeder dieser Schritte wird durch eine eigenständige Einheit realisiert, deren Funktionen selbst domänen- und anwendungsunabhängig sind. Die konkrete anwendungsspezifische Konfiguration basiert jeweils auf Regeln, die zur Laufzeit eingelesen und ausgewertet werden. Dies ermöglicht die anwendungsbezogene und zur Laufzeit konfigurierbare Filterung, Validierung und Interpretation beliebiger Quelldaten. Gleichzeitig können Erweiterungen zur Verarbeitung und Nutzung von Informationen aus beliebigen Dokumenten und Medientypen vorgenommen und unterschiedlich komplexe Analysemethoden zur Verarbeitung registrierter Dokumente und zur Extraktion enthaltener Informationen angebunden werden.
Prozesse, die den Lebenszyklus eines Dokumentes bestimmen (Entstehung, Nutzung, Speicherung, Archivierung und Ausgabe bis hin zur Löschung), können dazu führen, dass die einmal erstellte semantische Beschreibung nicht mehr den tatsächlichen Merkmalen oder Inhalten des Dokumentes entspricht. Im Rahmen dieses Projektes wurde daher ein Konzept zur langfristigen Aktualisierung und Synchronisierung des Datenmodells gegenüber einer Dokumentensammlung entwickelt. Dieses beruht ebenfalls auf einem Transformationsprozess, bei dem konfigurierbare Abbildungsregeln zum Einsatz kommen
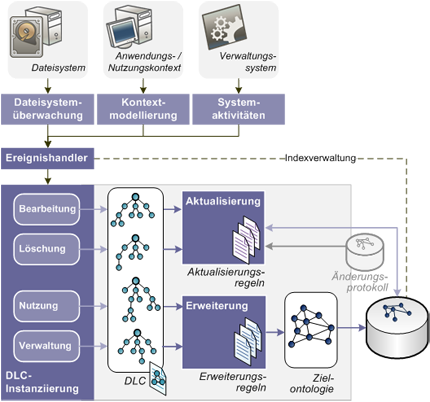
Im Rahmen dieser Arbeit wurde eine Document-Life-Cycle-Ontologie (DLC) zur Beschreibung von Dokumentaktivitäten entwickelt, mit deren Hilfe abhängig vom registrierten Ereignis ein temporäres Modell instanziiert und als Ausgangspunkt für den ausgelösten Abbildungsund Aktualisierungsprozess verwendet wird. Die Aktualisierung des Datenmodells, im Sinne des Löschens, Änderns oder Erweiterns von semantischen Informationen, erfolgt mit Hilfe domänenspezifischer Aktualisierungsregeln, die dynamisch geladenen werden. Um zu vermeiden, dass in der semantischen Datenbasis bestehende und damit gegebenenfalls durch den Nutzer bereits erweiterte oder bearbeitete Daten überschrieben oder auch entfernt werden, wurde ein Ansatz entwickelt, Nutzereingaben gesondert zu protokollieren und diese Protokolle beim Überschreiben von Dokumentenbeschreibungen zu überprüfen. Die Registrierung der Dokumentaktivitäten, die zur Modellierung der Beschreibung entsprechend der DLC-Ontologie führt, basiert auf der plattformspezifischen Überwachung von Dateisystemoperationen und der Berücksichtigung von verfügbarem Anwendungskontext, der durch einen externen Kontextmodellierungsdienst bereitgestellt wird.
Der in diesem Projekt entwickelte Prozess der Konsolidierung der semantischen Datenbasis umfasst die Erkennung und Beseitigung von Duplikaten, die Behandlung semantischer Fehler und Konflikte und die Behandlung unvollständiger Daten.
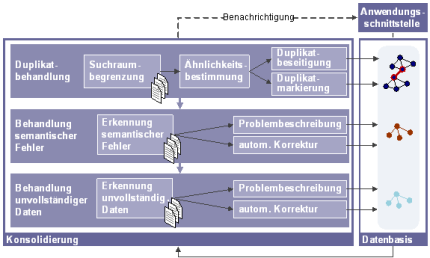
Die Erkennung von Duplikaten in einem semantischen Modell beruht auf einem effizienzorientierten Ansatz, der zunächst ontologieabhängig eine Suchraumbegrenzung anhand signifikanter Attribute je Objekttyp vornimmt und anschließend mögliche Duplikate durch eine ontologieunabhängige Ähnlichkeitsberechnung untersucht. Die Beseitigung der identifizierten Duplikate erfolgt ebenfalls ontologieunabhängig. Die Behandlung semantischer Konflikte und unvollständiger Daten beruht auf der Anwendung dynamisch geladener Regeln. Diese können an die jeweilige Anwendungsdomäne angepasst und auch durch Regeln zur Auflösung der Probleme ergänzt werden. Da dies jedoch in vielen Fällen nicht möglich ist, beruht das standardmäßige Vorgehen auf der Beschreibung des identifizierten Problems zur weiteren Verarbeitung. Zur Modellierung dieser Problembeschreibungen wurde eine eigene Ontologie entwickelt, die die nötigen Konzepte und Relationen zur Verfügung stellt und identifizierte Probleme in einer sowohl menschen- als auch maschinenlesbaren Form notiert. Dies ermöglicht die semiautomatische Auflösung von semantischen Konflikten bzw. unvollständigen Daten durch entsprechendes Nutzerfeedback.
Die oben beschriebenen Verfahren stellen die konzeptionelle Grundlage für eine semantikbasierte Verwaltung persönlicher, multimedialer Dokumente dar. Für die technische Realisierung dieser Mechanismen ist eine erweiterbare und flexible Architektur notwendig, auf die ein Entwickler einer PIM-Anwendung über eine entsprechende Anwendungsschnittstelle aufbauen kann und die ihm eine möglichst komfortable und einfach zu konfigurierende Implementierungsgrundlage im Sinne einer Service-Plattform bietet. Die entwickelte Architektur beruht auf einem komponentenbasierten Ansatz und gliedert sich in drei Ebenen: die medien- und systemspezifische Ebene der Dokumentenanalyse, die domänenunabhängige Ebene der semantischen Datenmodellierung und -verarbeitung und die domänenspezifische Ebene der Anwendungsschnittstelle. Durch diese ebenenweise Gliederung ergibt sich eine klare Trennung zwischen domänenunabhängiger und domänenabhängiger Anwendungslogik, welche die Anpassung an spezifische Anwendungsdomänen unterstützt.
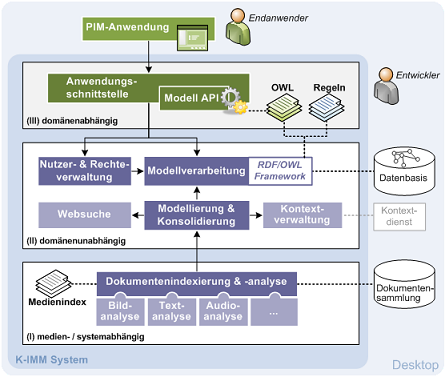
Zum Zwecke der Erprobung und Evaluation wurde eine prototypische OSGi-basierte Java-Implementierung realisiert.Diese umfasst Komponenten zur Verwaltung und Verarbeitung der Datenbasis und Systemkomponenten zum Import und Analyse von Medienobjekten. Des Weiteren existieren prototypische Umsetzungen zur Akquisition von semantischen Informationen aus dem WWW und von semantischen Kontextinformationen von Anwendungsdaten. Zur Unterstützung format- und technologieunabhängiger Wissensmodellierung wurde eine generische API implementiert, die bequem erweitert werden kann. Durch das hohe Maß an Erweiterbarkeit und Flexibilität, welche durch die generische Datenbasis und das Plugin-Konzept realisiert sind, lassen sich neue Systembestandteile bequem integrieren und verarbeiten. So lassen sich weitere Komponenten zur Unterstützung bestimmter Medientypen, diverse Oberflächenprototypen, plattformspezifische Dateisystemanbindungen, oder differenzierte Datenbasisschemata angliedern.
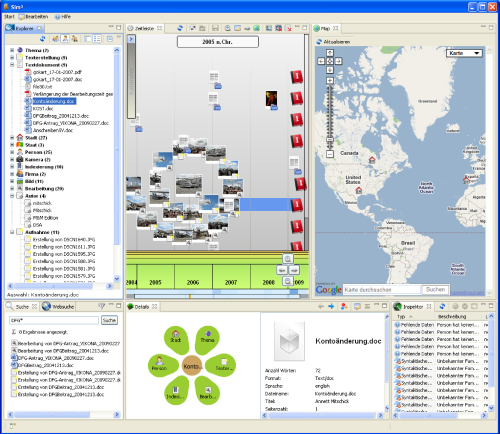
Um die praktische Tauglichkeit des entwickelten Ansatzes zu überprüfen, wurde das implementierte K-IMM System in verschiedenen Anwendungsszenarien eingesetzt. Als primäres Beispielszenario wurde die prototypische Desktop-Anwendung Sim² auf Basis der Eclipse Rich Client Platform (RCP) entwickelt. Die Referenzimplementierung des K-IMM-Systems kommt hierbei lokal zum Einsatz und verwaltet im Dateisystem abgelegte Bild-, Text- und Audiodokumente. Zum Einsatz kommen Analysekomponenten zur Unterstützung entsprechender Dokumentformate. Die Konzeption und Implementierung der grafischen Oberfläche entstand im Rahmen von Komplexpraktika (KP 2007/08, KP 2008/09). Im Wesentlichen bestand dabei die Zielsetzung darin, geeignete Interaktions- und Visualisierungstechniken zu nutzen, um die Stärken einer semantikbasierten Dokumentenverwaltung hervorzuheben.