Mit steigender Tendenz werden heute in nahezu allen Bereichen des beruflichen und privaten Lebens unterschiedlichste Daten gesammelt und aufbewahrt. Hieraus für den Menschen interessante sowie einfach nutzbare Informationen zu extrahieren und zu kommunizieren, stellt jedoch nach wie vor eine der großen Herausforderung der IT-Branche dar. Einer der möglichen Lösungswege wird durch das Forschungsgebiet der (Informations-)Visualisierung beschrieben. Dessen Ziel ist die ideale visuelle Repräsentation von Daten für die jeweils spezifischen Anwendungsfälle.
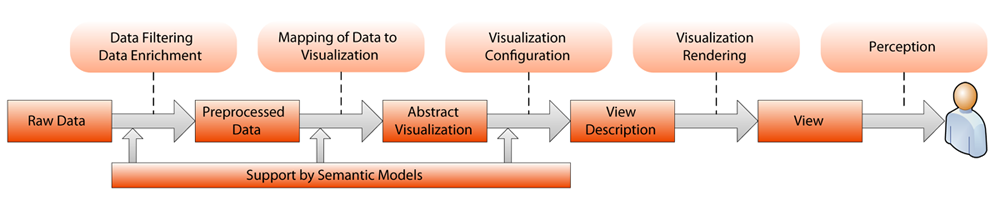
Obwohl in den letzten Jahrzehnten viele Forschungsergebnisse und Werkzeuge im Gebiet der Informationsvisualisierung entstanden sind, können noch viele Herausforderungen identifiziert werden, von denen folgende im Rahmen des Forschungsprojekts Mefisto aufgegriffen werden. Ein Problem stellt der teilweise geringe Automatisierungsgrad des Visualisierungsprozesses dar. So muss ein Anwender gezielt den Prozess konfigurieren, um eine für ihn nützliche Darstellung der Daten zu erhalten, auch wenn diesem das nötige Vorwissen aus der Domäne der visuellen Analyse fehlt. Ein Grund hierfür ist, dass existierende Werkzeuge zumeist nur die Struktur der zu visualisierenden Daten analysieren, wobei deren implizite Semantik und das Wissen aus deren Domäne ungenutzt bleiben. Ein weiteres Problem ist die unzureichende Verwendung des Nutzer- und Systemkontexts in den unten skizzierten Prozessschritten, so dass Daten nur selten situationsgerecht mit den vorhandenen Visualisierungstechniken dargestellt werden.
Für die Unterstützung des Visualisierungsprozesses mittels semantischer Informationen, so dass den oben skizzierten Problemen entgegnet werden kann, können die folgenden, aufeinander aufbauenden Zielstellungen identifiziert werden: